는 목차도 내용도 모든걸 그냥 다 엉터리 내 마음대로 지정했다
사실 보고서 자체는 ai의 도움을 많이 받았다
사용한 사이트 ...>< 제미나이, 지피티, 클로드, 노트북lm,이미지fx
ㅋㅋㅎㅎ사실상 이용할 수 있는건 다 이용했다고 생각하면 됨
그냥... 한번 해봤다~ㅎㅎ ^^
내가 생각한 문제점:
유튜브 내에서 너무 거짓 뉴스들과 가짜 정보들이 판을치는것같아서 그 진위 여부를 판독해주는 서비스를 만들면 어떨까!? 생각했음.... 타켓층은 부모님 세대를 둔 20~30대 자녀들? 평소에 엄마아빠 보면서 저걸 왜 믿지? 싶은 정보들의 대다수는 유튜브였던것같아서.... 이거에 답답함을 느낀 자식들아 너희가 구독료좀 대신 내드려라 하는 ~~ㅋ
이 서비스 기획의 가장 큰 문제점이 있음, 바로 설문조사를 가짜로 진행함 !!! ㅋㅋㅋ ㅠㅠㅠ 시간이 부족하기도 했고..(변명) 일단은 어떤식으로 돌아가는지 궁금했기에.. 실습 해봤음에 만족^^ㅎㅎ.. 최대한 다양한 연령대의 많은 설문조사 자료가 필요했는데 일단 제미나이에게 샘플데이터를 만들어달라고 부탁함. 그렇게 나온 설문조사지 시트가

이런식이다 !! psm 분석을 해봐야했기 때문에...(나중에 알았지만 샘플 개수가 좀 부족했다)
그래서 여튼 이 자료를 가지고 psm분석을 진행했다.
아래는 그 코드!!
# PSM 곡선 계산
def calculate_psm_curves(df, max_price=8000, step=250):
"""PSM 곡선 계산 함수"""
price_range = np.arange(0, max_price + step, step)
total_responses = len(df)
curves_data = []
for price in price_range:
too_cheap = len(df[df['min_price'] > price]) / total_responses * 100
too_expensive = len(df[df['max_price'] < price]) / total_responses * 100
not_too_cheap = 100 - too_cheap
not_too_expensive = 100 - too_expensive
acceptable = max(0, not_too_cheap - too_expensive)
curves_data.append({
'price': price,
'too_cheap': too_cheap,
'too_expensive': too_expensive,
'not_too_cheap': not_too_cheap,
'not_too_expensive': not_too_expensive,
'acceptable': acceptable
})
return pd.DataFrame(curves_data)
# PSM 곡선 데이터 생성
psm_df = calculate_psm_curves(df)
# 최적 가격점 계산
def find_optimal_points(psm_df):
"""최적 가격점들 찾기"""
opp = None # Optimal Price Point
pmc = None # Point of Marginal Cheapness
pme = None # Point of Marginal Expensiveness
for i in range(1, len(psm_df)):
curr = psm_df.iloc[i]
prev = psm_df.iloc[i-1]
# OPP: 너무 싸다와 너무 비싸다가 교차하는 점
if opp is None and prev['too_cheap'] >= prev['too_expensive'] and curr['too_cheap'] <= curr['too_expensive']:
opp = curr['price']
# PMC: 너무 싸지 않다와 너무 비싸다가 교차하는 점
if pmc is None and prev['not_too_cheap'] >= prev['too_expensive'] and curr['not_too_cheap'] <= curr['too_expensive']: pmc = curr['price']
# PME: 너무 싸다와 너무 비싸지 않다가 교차하는 점
if pme is None and prev['too_cheap'] >= prev['not_too_expensive'] and curr['too_cheap'] <= curr['not_too_expensive']: pme = curr['price']
return {'opp': opp, 'pmc': pmc, 'pme': pme}
optimal_points = find_optimal_points(psm_df)
print("\n🎯 최적 가격점")
print("-" * 30)
print(f"OPP (최적 가격점): {optimal_points['opp']:,}원" if optimal_points['opp'] else "OPP: 찾을 수 없음")
print(f"PMC (한계 저가점): {optimal_points['pmc']:,}원" if optimal_points['pmc'] else "PMC: 찾을 수 없음")
print(f"PME (한계 고가점): {optimal_points['pme']:,}원" if optimal_points['pme'] else "PME: 찾을 수 없음")
# 시각화 1: PSM 곡선
plt.figure(figsize=(14, 8))
plt.subplot(2, 2, 1)
plt.plot(psm_df['price'], psm_df['too_cheap'], 'r-', linewidth=3, label='너무 싸다', marker='o', markersize=3)
plt.plot(psm_df['price'], psm_df['too_expensive'], 'orange', linewidth=3, label='너무 비싸다', marker='s', markersize=3)
plt.plot(psm_df['price'], psm_df['not_too_cheap'], 'g--', linewidth=2, label='싸지 않다', alpha=0.7)
plt.plot(psm_df['price'], psm_df['not_too_expensive'], 'b--', linewidth=2, label='비싸지 않다', alpha=0.7)
# 최적가격점 표시
if optimal_points['opp']:
plt.axvline(x=optimal_points['opp'], color='purple', linestyle=':', linewidth=2, alpha=0.8)
plt.text(optimal_points['opp'], 50, f'OPP\n{optimal_points["opp"]:,}원',
ha='center', va='center', fontsize=10,
bbox=dict(boxstyle="round,pad=0.3", facecolor="yellow", alpha=0.7))
plt.xlabel('가격 (원)')
plt.ylabel('비율 (%)')
plt.title('PSM 가격 민감도 곡선', fontsize=14, fontweight='bold')
plt.legend()
plt.grid(True, alpha=0.3)
이건 코드의 일부이기 때문에!! (혹시 몰라서 파일을 올려두기)
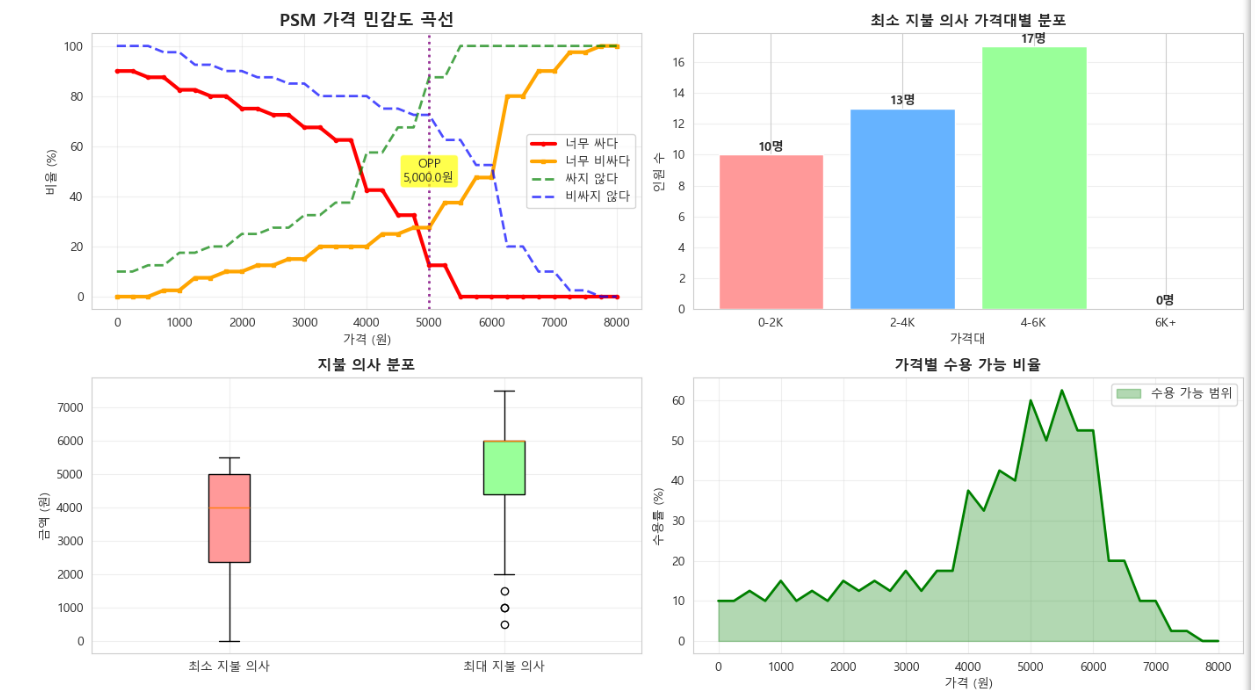
ㄴ출력결과......
그렇게 해서 이 결과를 토대로
**시장 규모 추정**
- TAM, SAM, SOM 프레임워크를 활용
- 연쇄비율법, 탑다운/다운탑 기법 등 다양한 방법론 언급2. **시장 상황 및 설명**
- 특정 시장에 대한 상황을 구체적으로 설명
- 해당 시장의 제품과 서비스 목적을 명확하게 기술3. **경쟁사 분석**
- 주요 경쟁사 확인 및 각 경쟁사의 점유율 추산
위 내용을 포함한다는 생각으로
난 최종 보고서를 작성해본것이야 ~~~!!!
내용이 너무 길어서 파일로 첨부 ㅎㅎㅎ 작성해봤다에 초점을 두었어요...
그리고 저번에 배운게 생각이 나서 html코드로 내 사업 계획서가 담기도록 만들어봄... netlify를 사용했고 이것은 그 링크!!
https://polite-gecko-765d6f.netlify.app/
나쁘지 않다고 생각한다...
마지막으로는 imageFX라는 이미지 생성 사이트를 사용해보고싶어서
A cinematic YouTube thumbnail showing a split-screen scene: on the left, chaotic fake news icons, blurred video frames, and a bold red "FALSE" graphic stamp; on the right, a clear verified fact with a green check mark on a translucent floating screen, analyzed by a futuristic digital investigator with a magnifying glass. The style is dramatic, modern, and high-contrast with cinematic lighting, photorealistic details, no real logos, no readable text, no watermarks.
이런 프롬프트를 넣어봤고?? ImageFx
https://labs.google/fx/ko/tools/image-fx
ImageFX - labs.google/fx
cluttered artist studio, light shining through, welcoming content_copy복사
labs.google
는 다음과 같은 사진을 출력해주었다!!

하하하. 나름 마음에 들어
이다음에는 실제로 설문조사를 해서 큰 데이터 샘플을 얻은 후에 조사를 해보고싶다.
설문의 결과가 좋지 않을때 (내 사업 아이디어가 별로라는 평가를 받았을때) 느낄 마음의 상처 각오도 미리 해둬야 한다.
여튼 저번에 배웠던 powerbi시각화 기능도 이 보고서 쓸때 해볼 수 있지 않을까 싶어서 다음에는 그것도 해보고싶다 !!
나름 의미있는 ,,, 수업이었어 !!
'Ax Wave > Dx' 카테고리의 다른 글
| 11가지 개별 분석 방법론 + 그중에 뭘 선택해서 분석할것인가~~! (0) | 2025.09.25 |
|---|---|
| UX UI 관련 긍/부정 여론 분석하기 (0) | 2025.09.25 |
| 데이터 문제해결 기획 & 사례 (4) | 2025.09.22 |
| 구글 애널리틱스 분석 (1) | 2025.09.18 |
| power bi의 마지막 ... / sqlite와 함께 써보자 (0) | 2025.09.17 |