RAG란 무엇인가?
최근 생성형 AI가 다양한 업무 영역에 활용되면서, 모델이 단순히 언어 생성 능력만 갖추는 것을 넘어 정확하고 근거 있는 정보를 제공하는 능력이 중요해지고 있다. 그러나 일반적인 LLM은 학습된 시점 이후의 정보나 특정 문서의 내용을 알 수 없으며, 사내 문서·법령·지침 같은 전문 자료를 직접 인용하는 데에도 한계가 있다.
이 문제를 해결하기 위한 대표적인 기술이 RAG(Retrieval-Augmented Generation, 검색 기반 생성)이다.
RAG는 간단히 말해 “AI가 답변하기 전에 관련 문서를 먼저 찾아보고 그 내용을 기반으로 응답을 생성하는 방식”이다. 즉,
검색(Retrieval) + 생성(Generation)
두 과정을 결합해 더 정확하고 신뢰할 수 있는 AI 응답을 만든다.
왜 RAG가 필요한가?
- LLM은 ‘환각(hallucination)’ 문제로 실제 없는 내용을 만들어낼 수 있음
- 최신 데이터나 특정 조직 내부 문서를 학습하지 않은 경우 정확한 답변이 불가능함
- 법령·행정지침·민원 관련 정보처럼 정확성·신뢰성이 중요한 분야에서는 필수적
예를 들어, 내가 사용한 PDF들(예: 도로교통법, 폐기물관리법, 민원처리법)은 모두 정확한 조문을 기반으로 해야만 하는 문서다.
RAG를 활용하면 이러한 문서들을 벡터화하여 시스템이 실제 근거를 기반으로 답변하도록 만들 수 있다.
내가 구축할 RAG 시스템은?
이번 프로젝트에서는 다음 과정을 실제 구현한다:
- 문서 수집
- 법령 PDF(예: 도로교통법, 민원처리법 등)를 불러와 텍스트 추출
- 청킹(Chunking)
- 문서를 작은 단위로 나누어 AI가 의미 단위로 이해할 수 있게 처리
- 임베딩(Embedding)
- 텍스트 조각을 숫자 벡터로 변환하여 의미 기반 검색이 가능하게 함
- VectorDB 구축
- Supabase 등 벡터 데이터베이스에 임베딩된 데이터를 저장
- 검색 및 생성
- 사용자가 질문을 입력하면
→ 관련 문서 조각 검색(Retrieval)
→ AI 모델이 이를 참고해 답변(Generation)
- 사용자가 질문을 입력하면
- n8n으로 전체 프로세스 자동화
- 청킹, 임베딩, 저장, 검색, 응답까지 하나의 워크플로우로 연결
실습 목표
이번 프로젝트의 목표는 단순한 챗봇이 아니라,
“법령·행정 문서를 근거로 명확한 답변을 제공할 수 있는 RAG 기반 챗봇 시스템”을 만드는 것이다.
이를 통해 다음을 학습 및 실습하게 된다:
- RAG 파이프라인 전체 이해
- 문서 처리·청킹·임베딩의 개념
- VectorDB 활용
- n8n을 활용한 실제 자동화 시스템 구축
- PDF 소재를 기반으로 한 근거 기반 응답 생성
이제 실습을 진행해봅시다
1단계. n8n 실행 후 ‘파일 업로드 폼(Form)’ 만들기
cmd창에서 n8n을 실행하면 브라우저에서 에디터가 열린다. localhost:**** 주소형식
여기서 첫 번째 노드로 On form submission 노드를 추가한다.
- Form URL 자동 생성됨
- Form Title: RAG 업로드
- Form Description: RAG 업로드입니다.
- Field Name: file
- Element Type: File
- Multiple Files: ON
- 이 폼을 통해 PDF를 업로드하면 워크플로우가 자동으로 시작되도록 하는 단계이다.
2단계. 업로드된 PDF를 n8n에서 수신하기
폼에서 파일을 업로드하면
On form submission의 Output에 PDF 정보를 받게 된다.
출력 예:
- filename
- mimetype
- size
- submittedAt
- binary data(blob)

3단계. PDF → 텍스트 변환 (Default Data Loader)
두 번째 노드로 Default Data Loader를 연결한다.
- Type of Data: Binary
- Mode: Load All Input Data
- Data Format: Automatically Detect
- Text Splitting: Custom (추후 splitter로 넘기기 위해)
→ 이 노드가 PDF 파일을 텍스트로 변환해서 “pageContent” 형태로 출력한다.
즉, PDF 문서를 AI가 읽을 수 있는 ‘텍스트 데이터’로 만드는 과정이다.

4단계. 텍스트 청킹(Chunking) – Text Splitter
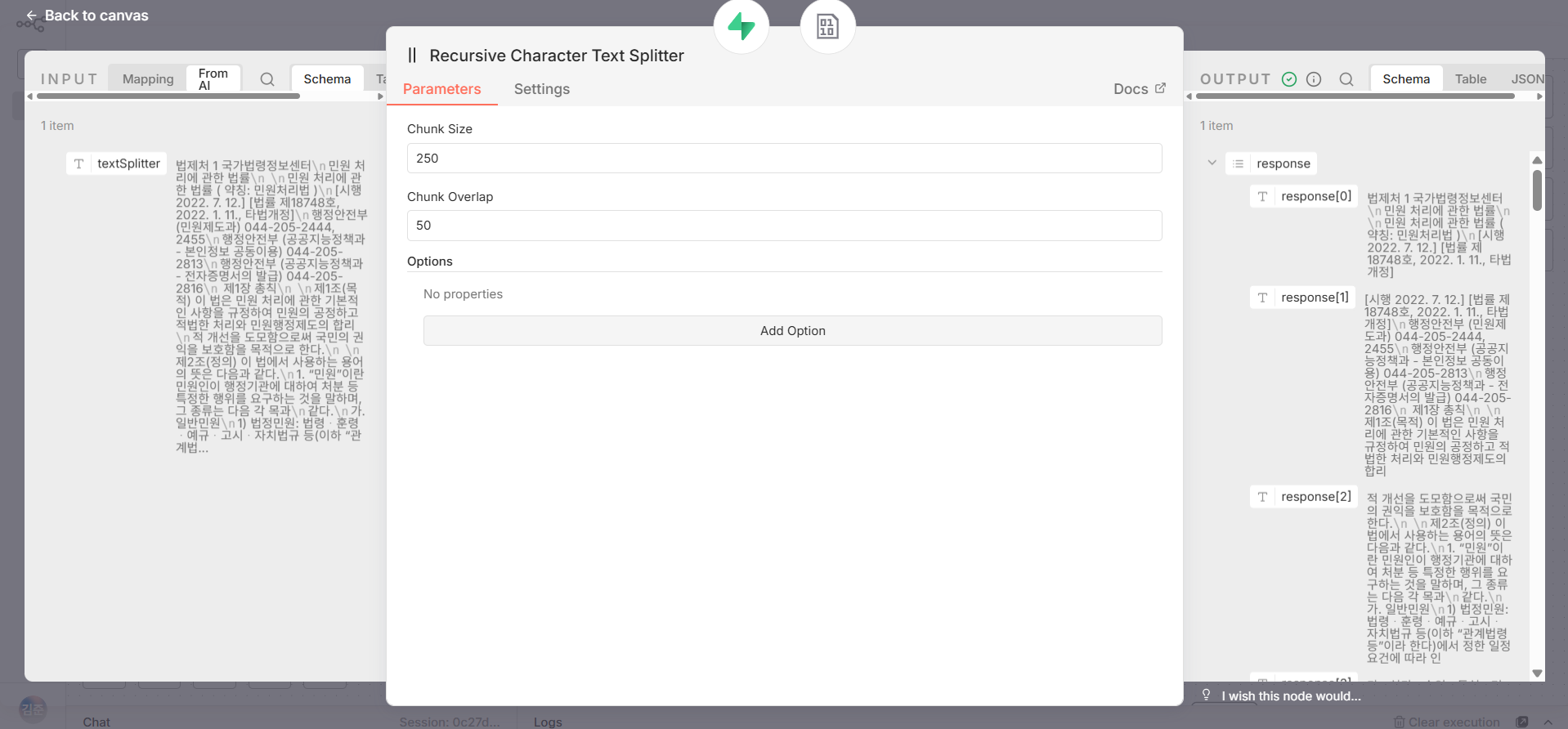
그 다음 Recursive Character Text Splitter 노드를 연결한다.
설정값:
- Chunk Size: 250
- Chunk Overlap: 50
이 단계에서 긴 문서가 작은 덩어리(Chunk)로 분할된다.
숫자를 저렇게 정한 기준은 그냥 느낌대로 간거라 나중에 바꿔도 됨
5단계. OpenAI Embedding 생성
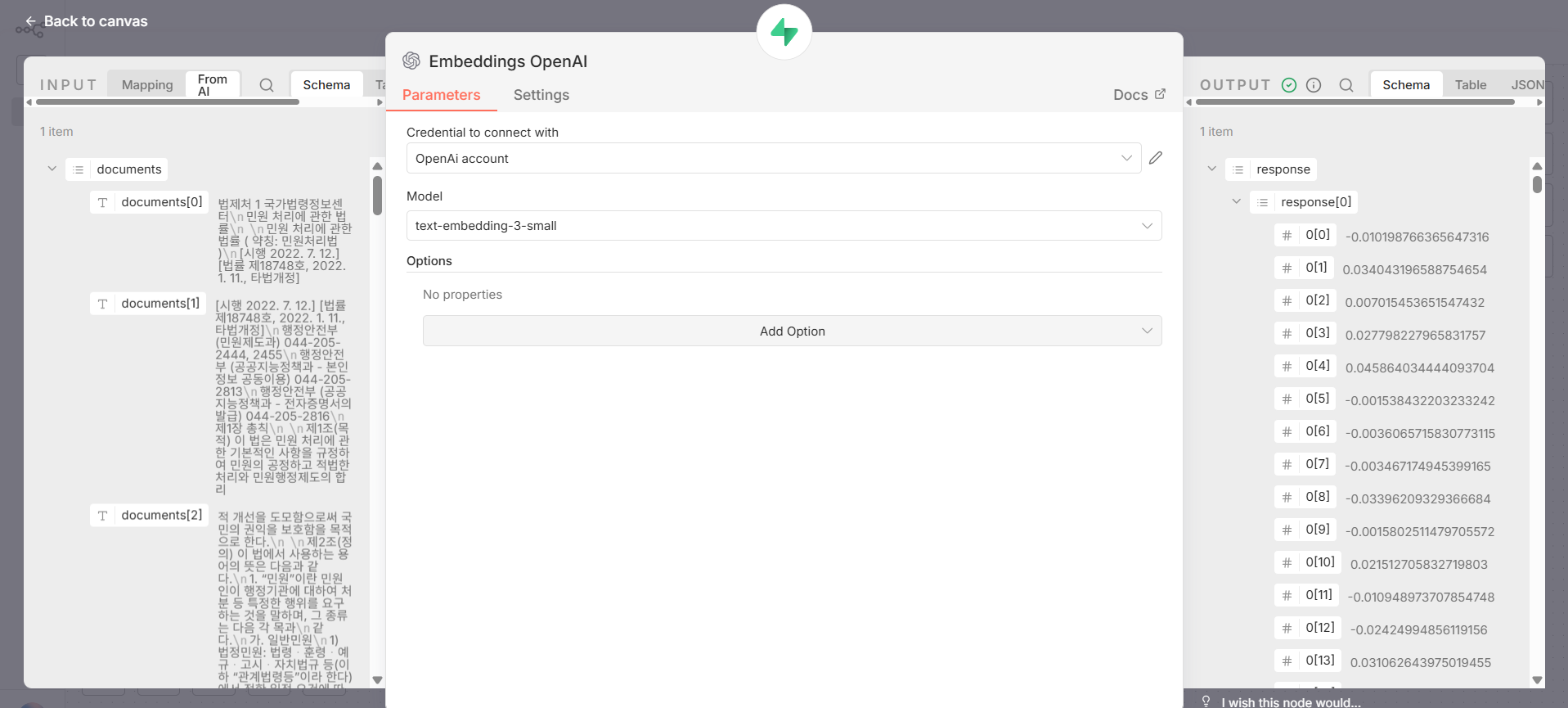
세 번째 핵심 노드가 Embeddings OpenAI 노드다.
- Model: text-embedding-3-small
(임베딩 차원: 1536)
출력은 다음과 같은 벡터 배열이다:
[0.01, -0.02, 0.03, ...]
각 텍스트 조각(chunk)이 숫자 벡터 형태로 변환됨
참고로 openai api는 따로 받아야됨
6단계. Supabase Vector Store에 저장
마지막으로, 청킹된 텍스트 + 생성된 임베딩을
Supabase Vector Store 노드로 보낸다.
설정:
- Operation Mode: Insert Documents
- Table Name: PDF에 맞는 테이블 선택
- 민원처리법 → documents_voc
- 도로교통법 → documents_road
- 폐기물관리법 → documents_trash
- Embedding Batch Size: 200
이 단계에서 Supabase에 아래 필드들이 저장됨
- content (chunk 텍스트)
- metadata (파일명 등)
- embedding (벡터 1536차원)
이렇게 PDF 하나를 처리하면 각 법령 테이블에 자동으로 insert된다.

7단계. 동일한 흐름으로 나머지 PDF도 처리
동일한 구조를 그대로 사용하되
Supabase Vector Store의 Table Name만 다르게 선택하여
- 민원처리법 → documents_voc
- 도로교통법 → documents_road
- 폐기물관리법 → documents_trash
이 세 가지 법령 PDF를 모두 업로드하고
각각의 테이블에 청킹 + 임베딩 + 저장을 완료했다.

안에 들어가보면 pdf의 텍스트들이

이런식으로 정리가 잘 되어있다
일단 지금까지는
“사용자가 업로드한 PDF를 n8n 폼으로 수신 → PDF를 텍스트로 변환 → 청킹 → 임베딩 생성 → Supabase의 법령별 테이블에 저장하는 전체 RAG 데이터 구축 파이프라인을 구성했다.”
전체 구조는 이런형태임

다음은 RAG 챗봇 실행 플로우를 구성 해야겠죠
좀 밑에 새롭게 플러스를 눌러서 When chat message received <- 이걸 끌어온다
다음 옆에 + 누르고 AI Agent를 불러와서 이렇게 설정해줬다
중요한 설정은 prompt를 chatInput으로 받고 (fix가 아닌 expression으로 설정 주의)
내가 질문을 했을 때 pdf자료 기반이 아닌 생성형 모델이 답변을 주는것일 수 있기 때문에 system message에 다음과 같은 명령어를 넣어주면 된다

에이전트 밑에 chat model은 위에랑 똑같은 api로 OpenAI Chat Model 연결해주면 된다
Memory 부분은 그냥 Simple Memory 해서

sessionID를 끌어오면 되고 Context Window Length <- 이거는 모델이 최대 5개의 대화를 기억할 수 있도록 설정하는것이다
이제는..AI Agent의 Tool 부분에는 데이터베이스를 연결해 주면 되는데 우선 pdf파일이 총 3개니까 이름에 맞춰서
roadDB, trashDB, vocDB 를 생성해준다
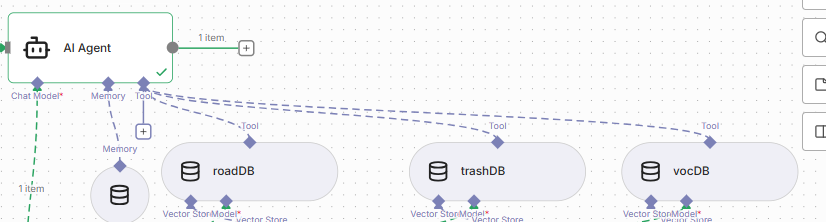
그리고 그 밑에 각각 해당하는 해당하는 슈퍼베이스를 연결해주면 되는데
Supabase Vector Store을 통해서 Table Name만 바꾼채 연결을 해주면 된다

마지막으로 총 세개의 슈퍼베이스 벡터 스토어의 Embedding부분에 Embeddings OpenAI 를 연결해주면 끝난다
이때도 api는 그냥 동일한거 쓰면 됨
그러면 최종 형태가 이렇게 된다

이제는 잘 됐나 테스트 해볼 시간
대표로 roadDB를 보겠
이건 실제 데이터

챗봇에게 다른 설명은 안하고 도로 제 72조 <-이렇게 물어봤다

이게 챗봇의 답변
잘 구현된 모습이다
실제로 채팅 입력하고 기다리면

이렇게 딱 맞는 DB에 접근해서 로딩되는게 보임
다음으로는 폐쇄망 RAG로 찾아오겠습니다
'Ax Wave > Ax' 카테고리의 다른 글
| 약봉지 스캔 & 의약품 검색 & 캘린더 저장 시스템 만들기- api key 활용 (1) | 2025.11.26 |
|---|---|
| Orange를 사용해 본 적이 있는가.. (0) | 2025.11.26 |