컴백이아냐 떠난적 없 으 니 까
프로젝트 기간으로 바빴습니다
이젠 그동안 뭘 했는지 정리할 시간이죠
**Orange(오렌지)**는 시각화 기반 데이터 분석·머신러닝 도구로, 코딩 없이도 다양한 알고리즘을 쉽게 적용할 수 있는 오픈소스 데이터 마이닝 플랫폼 입니다.
이번에 저도 프로젝트 하면서 처음 알았어요
느낀점부터 말하자면, 전처리 시 이상치를 가진 변수가 무엇인지 정확한 확인은 어려우나 제거가 용이하고
머신러닝 모델 파라미터 바꿔가면서 성능 테스트해보기에는 편할것같아요

우선 오렌지를 쓰기 위해 사용한 데이터는, 캐글데이터 입니다
데이터셋: LengthOfStay.csv (100,000명 환자)
데이터를 봤는데 의료 기관의 실제 환자 입원 기록 데이터 + 실제 입원 일수가 있길래
환자의 입원 일수를 예측하는 기계학습 모델 개발을 해보면 어떨까 생각했어요.
입원기간을 정확하게 예측하면 병원 자원관리나 병상 배정 계획을 더 효과적으로 세울 수 있을테니까요!?
우선 전체 데이터는 10만개 인데요, orange로 분석을 진행하기 전 엑셀 파일을 열어서, 분석에 불필요한 열이 있을까 확인해봤어요
참고로 결측값은 없는 데이터 입니다~!

따라서 환자 번호 eid, 입원 시작 일자 vdate, 퇴원일자 dischage 3개의 열은 분석에 필요하지 않다는 판단을 내렸습니다
discharge-vdate가 우리의 타겟변수 lengthofstay 이기 때문이죠 !!
orange에는 파일을 선택만 해도 변수 타입 설정 및 skip설정이 가능함
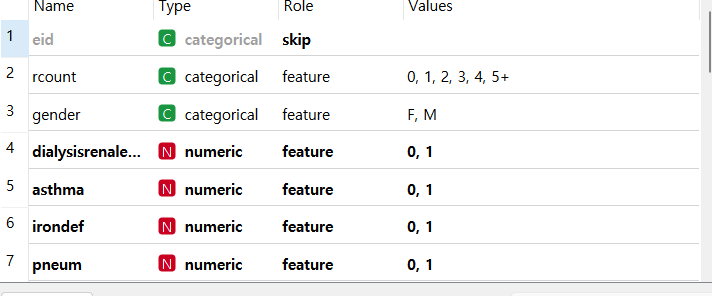
다른 변수들의 타입도 맞춰줬습니다.
facid(의료 시설 id), rcount(재입원 횟수), gender(성별) 범주형 변수 3개는 categorical, 나머지 질병 관련 변수 11개는 numeric으로 지정해주었습니다.
이제 데이터 전처리를 해줘야겠죠
우선 결측치가 있다면 여러가지 결측치 처리 방식으로 ( 평균값 대체, 결측치가 있는 열 제거, 중앙값으로 대체 등등) 처리를 했을테지만 결측치가 없는 데이터입니다.
중요한 점은 이상치 처리였는데요

orange의 "feature statics"위젯을 연결해보면

이런식으로 극단적인 이상치가 다수 존재함을 알 수 있었습니다
처음에는
이게 왜!? 어쩌라고!! 하고 그냥 분석 진행했는데, 강사님이 이상치 처리는 꼭 해줘야 하는 부분이라고 알려주셨어요 ㅎ
근데 저의 역량 부족이었을 수 있겠지만 오렌지에서는 이상치를 눈으로밖에 확인 못하더라고요? 그래서 이부분은 어쩔수없이 파이썬으로 이상치를 확인했습니다. 방식은 통계적으로 이상치를 제거하는것!
IQR(Interquartile Range) 방법론
이상치 제거를 위해 통계적으로 검증된 IQR(사분위수 범위) 방법
IQR은 데이터의 중앙 50%를 나타내 는 지표로, 극단값을 객관적으로 정의할 수 있다.
IQR 이상치 정의: 이상치 = Q1 - 1.5×IQR 미만 또는 Q3 + 1.5×IQR 초과
여기서 IQR = Q3 - Q1 Q1: 1사분위수 (25%), Q3: 3사분위수 (75%)
그냥 갑자기 배운게 생각나서 통계적 이상치! 에헿ㅎㅎ헿ㅎㅎ 이러면서 적용했어요

예를들어 hematocrit의 경우 q1이 10.9, q3이 12.9이므로 IQR을 2.0, 따라서 7.9미만 또는 15.9 초과는 이상치로 간주하여 제거한 것입니다.
오렌지의 select rows에서

이렇게 조건문 형식으로 처리가 가능합니다
여기서 bloodureanltro( 혈중 요소질소 (mg/dL) - 신장 기능 지표 )에 집중해주세요... 뒤에가서..이유를 말씀드릴게요
그 다음으로는 continuize에서 범주형 변수를 one-hot 인코딩 방식으로 인코딩을 해주었어요
Categorical Variables: One-hot encoding 선택 -> 총 13개의 더미 변수가 생성되어, 원본 3개 범주형 변수를 대체함
Numeric Variables: Keep as it is 선택

한가지 문제점이 있습니다
많은 변수들이 우측으로 치우친 분포(right-skewed)를 보이고 있었죠, 이는
1. 선형 모델의 성능 저하 초래 2. 정규성 가정을 위반 3. 이상치의 영향력 증폭 위험이 있기 때문에
왜도 변환이 필요하다고 느꼈습니다!
여기서도 통계학에서 배운 내용을 써먹었는데요, (맞는지는 모름 ^^)

이런 흐릿한 기억이 나서요
이 왜도 평가도 파이썬으로 진행했습니다
오렌지에서는 formula를 사용하면 이런식으로 식을 써서 왜도 보정이 가능해요


여기까지 한거 feature statics로 다시 보니까 이런식으로 보정이 됐긴 됐더라고요
이게 맞는지 확신은 없어요 근데 강사님이 잘했다고 하시는거보니..
ㅎ
다음에는 또 formula를 써서 feature engineeering을 해보려고해요...
도메인 지식을 좀 첨가해서 에측력을 높이는 복합 지표를 만들어보려는 계획입니다
여기부터 그냥 뇌피셜 + 도메인(을 가장한 클로드님과 나의 합작) 이라 진지하게 보지 말아주세요

총 5개 변수를 생성한거죠

나...자신을 믿고.....진행할것

후에 왜도 변환 한 열은 새로 만든거니까 기존 변수는 ignored를 진행해주고요
이제 평화롭게 모델을 돌리려고 마지막으로 그래프를 봤는데 아니 글쎄 제가 만든 feature들도 이상치?가 있는거에요 ㅎ...

그래서 이것들도 급하게 파이썬으로 이상치 확인하고 보정을 진행해줍니다
이 단계가 맞는건진 모르겠어요 저도 ㅎㅎ
아하하! 아하하하! 아하하하하하
이제 전처리는 끝났(다고판단했)어요
10만개로 시작해서 총 8만1천개의 데이터가 나오더랍니다 !!
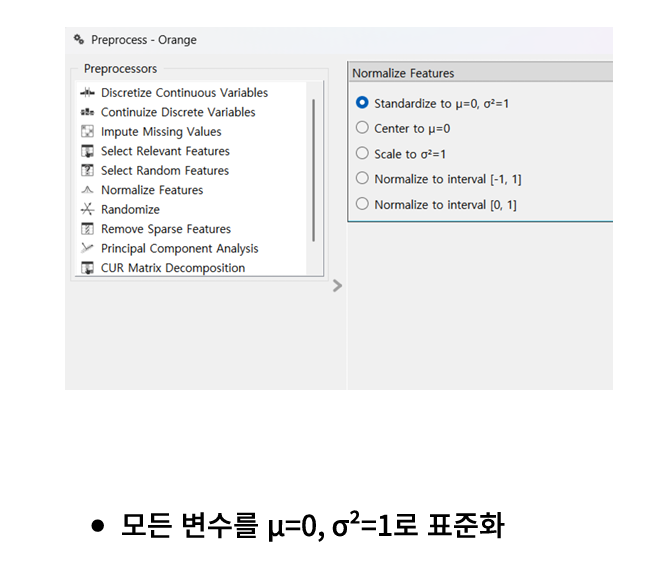
preprocess 위젯은 이런식으로 변수 표준화를 해줄 수 있습니다
후,,이제 모델을 돌려보자
data sampler위젯을 사용하면
Sampling type: Fixed proportion
Train set: 70% (70,000개)
Test set: 30% (30,000개)
Stratified: 체크 (Target 변수 분포 유지)
Replicable: 체크 (seed: 42) - 재현 가능성 보장
이런식으로 모델 설정이 가능하세요
이 다음이 헷갈리고 중요한데요, train/ test셋을 정확히 나눠야하잖아요

저 줄 위에 텍스트가 있어요
train으로 연결되는 선은 data sample-> data 이고 test로 연결되는 선은 resuming data->data인거 보이시죠?
줄 더블클릭하면 따로 설정 가능한 부분이에요 이래야 데이터셋이 7:3으로 나눠지는것임

저는 일단 첫번째 실험으로 선형회귀, 랜덤포리스트, svm, tree 모델 4개의 성능을 비교했습니다

결론은 뭐 이랬는데
( 가장 성능이 좋았던 랜덤포리스트 기준으로 오렌지의 prediction과 scatter plot을 사용해 추가 분석을 진행 )
발표하신분들 다 들어봐도 그렇고 제가 계속 이상했던게 다들 랜덤포리스트 성능이 제일 높은거에요
그런데? 학교에서 배웠던게 좀 스멀스멀 생각나서 찾아보니까 랜덤포리스트가 이상치에 강건하다네요
그래서 그냥 제가 생각하기에는 이상치에 강건하기 때문에 성능이 저렇게 높게 나온거 아닌가 싶어요
여튼~ 추가적인 분석을 진행하기위해 그래도 제일 성능이 높았던 랜덤포리스트를 가지고
단일 테스트와 10-fold 교차검증을 비교했어요

인공지능학과라면 아시겠지만.. leave-one-out, cross validation 등등 귀에 딱지가 얹도록 들었던것들인데 막상 적용은 파이썬 코드 몇줄로 해결했잖아요? 이렇게 옵션으로 설정할 수 있어서 신기했어요
교수님이 항상 강조해주셨던걸 기억해보자면 validation data와 train data를 명확하게 분리해라, 라고 하셨던게 기억이 나는데 그건 오렌지가 알아서 해줬겠죠? 여튼 실제 실험에는 10fold로 설정하고 성능을 비교했습니다

이것도 어쨋든 발표하려고 만든 장표인데
뭐 말을 하자면 10fold와 단일 테스트 성능 차이가 거의 없으니까 모델이 안정하다 이렇게 말 할 수 있겠지만
이상치가 계속 걸려요 이상치.....
그래서 마지막 실험이라는것은...
선형회귀가 이상치에 민감하다고들 하잖아요?
선형회귀로 분석해보자 ~~~ 라는 생각..
이상치 제거 전과 후 성능을 비교했어요

결과입니다
예! 꽤 의미있는 결과가 나왔다고 볼 수 있겠죠
확실히 선형회귀는 이상치 처리가 중요한가봅니다
예 이렇게 3가지의 실험을 마쳤어요...

발표 피피티를 이렇게 만들다니
진짜 상여자 아닌가요?
농담입니다 시간이 없었어요
어쨋든 제가 실제로 느낀점이긴 합니다
아직도 정답은 잘 모르겠어요
그리고 의료데이터라는게 원래 이상치를 제거 해도 되는건가요?
아까 제가 bloodureanltro( 혈중 요소질소 (mg/dL) - 신장 기능 지표 ) 에 집중해달라고 말씀을 드렸잖아요
이게 5~20사이로 이상치를 제거한건데 이게 무려 682라는 값이 있었어요
통계적으로는 매우 확실한 이상치 이지만 의료적으로는 중증 신부전을 의미하기때문에 맥락적으로 의료적 이상치를 고려해줘야 하는건가? 하는 의문이 있었어요 아니면 신부전 환자의 입원 일수만 따로 예측을 한다던가 하는...
개선 방안 고려 부분에서는
학교에서 수업 들으면서 여기저기서 주워들은 단어들을 정리한겁니다 도움을 좀 받긴 했어요
근데 사실~ 파이썬으로 분석하면 다 해볼 수 있는 부분이긴 합니다 오렌지에서 어떻게 하는건지 모르겠어요

어쨋든 그리하여~ 생성된 저의 총 워크스페이스입니다
오렌지 재밌네요 근데 맞게 한건지는 모르겠어요
다음에 또 해봐야겠습니다.....투비컨티뉴
'Ax Wave > Ax' 카테고리의 다른 글
| n8n을 통해 오픈망 RAG 시스템 구축하기 (0) | 2025.12.03 |
|---|---|
| 약봉지 스캔 & 의약품 검색 & 캘린더 저장 시스템 만들기- api key 활용 (1) | 2025.11.26 |